In the wake of recognizing the potential to augment Large Language Models (LLMs) with proprietary data, considerable discourse has arisen regarding the optimal approach for effectively bridging the gap between the LLM’s general knowledge and proprietary datasets. A pivotal point of contention revolves around the comparison of fine-tuning and Retrieval-Augmented Generation (RAG) techniques, with the unequivocal conclusion being that a combination of both methodologies yields optimal results.
This article meticulously delves into the intricacies of the Retrieval-Augmented Generation (RAG) framework, commencing with an in-depth exploration of its theoretical underpinnings. Subsequently, it expounds upon the practical implementation of a RAG pipeline, elucidating the orchestration process employing LangChain, the integration of OpenAI language models, and the utilization of a Weaviate vector database to enhance retrieval mechanisms.
What is Retrieval-Augmented Generation?
Retrieval-augmented generation (RAG) represents an advanced paradigm aimed at endowing Language Models (LLMs) with augmented information retrieved from external knowledge sources. By integrating this supplementary data, LLMs can proficiently generate responses that exhibit enhanced accuracy and contextual relevance, thereby mitigating instances of hallucinatory outputs.
Issue
Cutting-edge Large Language Models (LLMs) leverage extensive datasets for training, aiming to encompass a diverse range of general knowledge encoded within the neural network’s parametric memory. Nonetheless, soliciting an LLM to produce a completion necessitating information beyond its training data—such as recent, proprietary, or domain-specific data—may result in factual inaccuracies, commonly referred to as hallucinations. The phenomenon is exemplified in the accompanying screenshot :
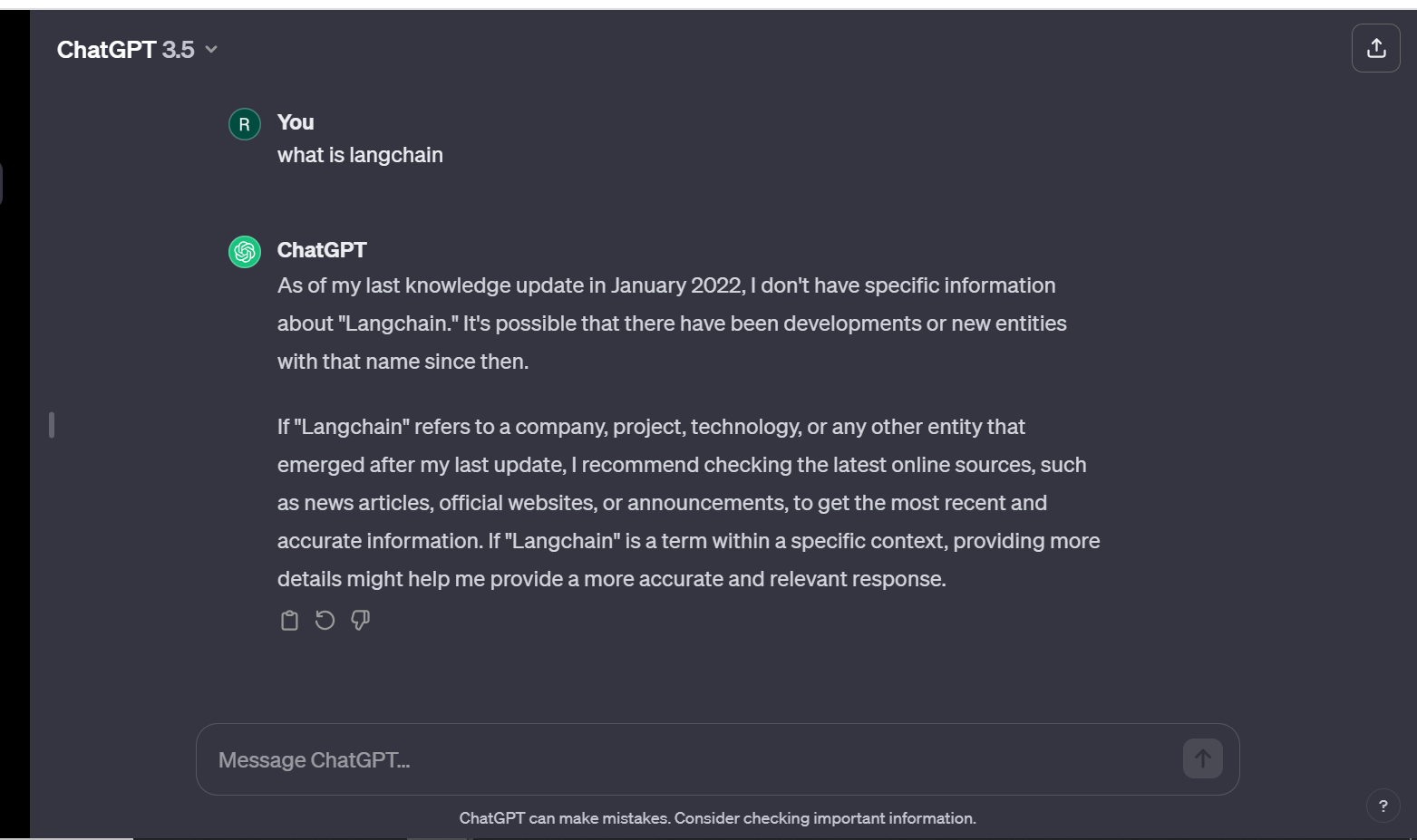
It is imperative to mitigate the disparity between the Language Model’s (LLM) inherent general knowledge and supplementary contextual information. This proactive approach serves to optimize the LLM’s capacity for generating precise and contextually nuanced completions, concurrently minimizing the occurrence of hallucinatory outputs.
Resolution
Historically, the customization of neural networks for domain-specific or proprietary data involved the meticulous fine-tuning of models. While this approach has demonstrated efficacy, it is characterized by computationally intensive processes, significant cost implications, and a prerequisite for substantial technical expertise, thereby diminishing its adaptability to rapidly evolving information landscapes.
In 2020, Lewis et al. introduced a paradigm-shifting methodology known as Retrieval-Augmented Generation (RAG), as elucidated in their paperwork titled “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks“. This innovative framework amalgamates a generative model with a retriever module, enabling the incorporation of supplementary information sourced from external knowledge repositories. Notably, this approach facilitates seamless updates to the external knowledge source, enhancing the adaptability and responsiveness of the overall system.
Relational Access Guidance (RAG) Framework
In succinct terms, the Relational Access Guidance (RAG) framework can be analogously likened to the relationship between Language Models (LLMs) and an open-book examination within the domain of artificial intelligence. Much like the allowance of reference materials in an open-book exam facilitates the retrieval of pertinent information for human response, RAG segregates factual knowledge from LLMs’ reasoning faculties. This is achieved through the maintenance of an externalized knowledge repository, ensuring seamless accessibility and dynamic updates.
The bifurcation of knowledge in the RAG framework consists of two distinct categories:
Parametric Knowledge: Acquired implicitly during the model’s training phase and intricately encoded within the neural network’s weights.
Non-parametric Knowledge: Deliberately extricated and preserved in an external knowledge repository, exemplified by a vector database. This segregation echoes the objective of emphasizing the LLM’s cognitive reasoning capacities over the rote memorization of specific details.
It is pertinent to acknowledge that JJ initially posited the ingenious analogy between RAG and an open-book exam during the Kaggle — LLM Science Exam competition.

Retrieve: The user query serves as the catalyst for extracting pertinent context from an external knowledge source. In this process, the user query undergoes embedding using a sophisticated model, aligning it within the same vector space as the supplementary context stored in the vector database. This alignment facilitates a nuanced similarity search, ultimately yielding the retrieval of the top k closest data objects from the vector database.
Augment: The user query and the procured additional context seamlessly integrate into a meticulously designed prompt template.
Generate: Subsequently, the retrieval-augmented prompt is seamlessly channeled into the Language Model (LLM) for the final generation phase.
Retrieval-Augmented Generation Implementation using LangChain
This segment deploys a RAG (Retrieval-Augmented Generation) pipeline in Python, harnessing the power of an OpenAI Language Model (LLM) in tandem with a Weaviate vector database and an OpenAI embedding model. The orchestration is facilitated through the utilization of LangChain.
Prerequisites
Ensure that you have installed the essential Python packages for optimal functionality:
- Langchain – utilized for orchestration purposes.
- Openai – indispensable for the embedding model and Large Language Model (LLM) integration.
- Weaviate-client – necessary for seamless interaction with the vector database.
| !pip install langchain openai weaviate-client |
Furthermore, define your relevant environment variables in a .env file in your root directory. To procure an OpenAI API Key, it is imperative to possess an active OpenAI account. Subsequently, navigate to the API keys section and initiate the process by selecting the option to “Create a new secret key.”
| OPENAI_API_KEY=“<YOUR_OPENAI_API_KEY>” |
Then, run the following command to load the relevant environment variables.
| import dotenv
dotenv.load_dotenv() |
Preparation
In the initial phase of preparation, it is imperative to assemble a comprehensive vector database serving as an external knowledge repository containing pertinent supplementary information. The construction of this vector database involves a systematic sequence of actions:
- Acquire and Load Data
- Document Chunking
- Embedding and Storage of Chunks
The initial step involves collecting and loading your data. In this instance, we will utilize Langchain documentation to provide additional context. To facilitate data loading, one can employ any of LangChain’s numerous built-in DocumentLoaders. A Document, in this context, refers to a dictionary containing both text and metadata. For loading the text specifically, LangChain’s WebBaseLoader will be employed.
| import requests
from langchain.document_loaders import WebBaseLoader url = “https://python.langchain.com/docs/get_started/introduction” loader = WebBaseLoader(url) documents = loader.load() |
Next, segment your documents—The original document is too lengthy to seamlessly fit into the context window of the LLM. Therefore, it is necessary to divide it into smaller sections. LangChain provides several built-in text splitters designed for this purpose. In this straightforward example, the CharacterTextSplitter can be employed, setting the chunk size to approximately 500 and a chunk overlap of 50 to maintain textual coherence across the chunks.
| from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50) chunks = text_splitter.split_documents(documents) |
Finally, embed and store the chunks — To facilitate semantic search across the text chunks, it is essential to generate vector embeddings for each chunk and subsequently store them alongside their respective embeddings. Utilizing the OpenAI embedding model allows for the creation of these vector embeddings, while the Weaviate vector database serves as an effective storage solution. The vector database is seamlessly populated with the chunks by invoking the .from_documents() method.
| from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate import weaviate from weaviate.embedded import EmbeddedOptions client = weaviate.Client( embedded_options = EmbeddedOptions() ) vectorstore = Weaviate.from_documents( client = client, documents = chunks, embedding = OpenAIEmbeddings(), by_text = False ) |
Step 1: Retrieve
Once the vector database has been populated, you have the option to designate it as the retriever component. This component is responsible for fetching additional context by leveraging semantic similarity between the user’s query and the embedded chunks.
| retriever = vectorstore.as_retriever() |
Step 2: Augment
To further enrich the prompt with additional context, it is essential to create a prompt template. The prompt can be effortlessly tailored using a template, as demonstrated below.
| from langchain.prompts import ChatPromptTemplate
template = “””You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don’t know the answer, just say that you don’t know. Use three sentences maximum and keep the answer concise. Question: {question} Context: {context} Answer: “”” prompt = ChatPromptTemplate.from_template(template) print(prompt) |
Step 3: Generate
Ultimately, you have the ability to construct a chain for the RAG pipeline by linking the retriever, the prompt template, and the LLM. Once the RAG chain is established, you can then invoke it.
| from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough from langchain.schema.output_parser import StrOutputParser llm = ChatOpenAI(model_name=”gpt-3.5-turbo”, temperature=0) rag_chain = ( {“context”: retriever, “question”: RunnablePassthrough()} | prompt | llm | StrOutputParser() ) query = “what is langchain?” rag_chain.invoke(query) |
To Sum it up:
This article delves into the intricacies of Retrieval-Augmented Generation (RAG), a concept introduced in the influential paper titled “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” published in 2020.
The execution of the RAG pipeline is meticulously detailed, leveraging the synergies between an OpenAI Language Model (LLM), a Weaviate vector database, and an OpenAI embedding model. The orchestration of these components is skillfully managed using LangChain. This article not only unravels the conceptual intricacies but also provides a hands-on approach to the application of RAG, making it an insightful and practical resource for those engaged in knowledge-intensive Natural Language Processing (NLP) tasks.








