Language models are computer programs that can generate text similar to how humans do. But what makes a piece of text “good” can vary depending on the situation, and it’s hard for a computer to understand this.
Most language models today use a method called “next-token prediction” to generate text. This means they predict the next word based on the words they’ve seen so far. But this method isn’t perfect, and sometimes the text doesn’t make sense or meet the user’s needs.
To solve this problem, researchers have proposed using human feedback to train language models. This approach, called “Reinforcement Learning from Human Feedback” (RLHF), uses feedback from humans to guide the learning process of the model. This way, the model can better understand what humans consider “good” text.
In simple terms, RLHF is like having a teacher who guides the model in learning how to write better. This can lead to better results, whether the model is writing a story, providing information, or even generating code.
So, by using human feedback, we can make language models better at understanding and meeting our needs.
What is RLHF ?
Reinforcement Learning From Human Feedback (RLHF) is a method to train AI systems. It combines reinforcement learning, where an AI learns by interacting with its environment and getting rewards or penalties, with human feedback. The aim is for the AI to get the most rewards over time.
In RLHF, human feedback is used to create a reward signal. This signal helps to improve the AI’s behavior. This method is useful because it allows the AI to understand human preferences better.
For example, RLHF can be used to train self-driving cars to drive safely in busy city streets by understanding and predicting human behavior. As AI becomes more common in our lives, techniques like RLHF will be more important to help AI interact with humans safely and effectively.
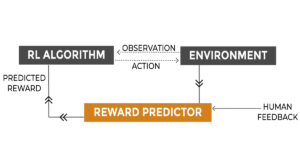
How does it work ?
The process of Reinforcement Learning with Human Feedback (RLHF) involves several essential steps that lead to the continuous improvement of an AI model’s performance. Let’s take a closer look at these steps:
1. Initial model training: In this first step, the AI model is trained using supervised learning, where human trainers provide labeled examples of correct behavior. This helps the model to predict the appropriate action or output based on the given inputs. This stage is critical because it lays the foundation for the subsequent stages of RLHF.
2. Feedback collection: After the initial model training, human trainers provide feedback on the model’s performance, ranking various model-generated outputs or actions based on their quality or correctness. This feedback is crucial because it creates a reward signal for the next step of RLHF.
3. Fine-tuning with reinforcement learning: In this stage, the model is fine-tuned using Proximal Policy Optimization (PPO) or comparable algorithms that integrate the reward signals provided by human trainers. The model’s performance continues to improve as it learns from the feedback provided by human trainers.
4. Iterative process: The final step of RLHF is the iterative process of collecting human feedback and refining the model via reinforcement learning, resulting in continuous improvement in the model’s performance. This step ensures that the model adapts to new situations and continues to learn from its mistakes.
RLHF is an essential technique for developing robust and effective AI models that can perform complex tasks. By incorporating human feedback into the training process, the model can learn from real-world situations and improve its performance over time.
As AI technology continues to evolve, RLHF will undoubtedly become even more critical for creating AI models that can operate safely and efficiently in a wide range of contexts.
Open Source Tools for RLHF
Reinforcement Learning for Language Models (RLHF) is a field that has grown a lot since 2019. There are now many tools for RLHF in PyTorch, including Transformers Reinforcement Learning (TRL), TRLX, and Reinforcement Learning for Language Models (RL4LMs).
TRL is used to fine-tune pre-trained language models using a method called Proximal Policy Optimization (PPO). TRLX is a bigger version that can handle larger models and can be used for both online and offline training. It’s good for people who are experienced in large-scale modeling.
RL4LMs is a library that has many parts for fine-tuning and testing language models with different RL algorithms. It’s very flexible and can train any transformer-based language model. It’s also been tested on many tasks, which gives us useful information about different issues.
Both TRLX and RL4LMs are being improved all the time, and we can expect new features soon. Also, Anthropic’s big dataset is now available on the Hub, which adds to the resources for RLHF.
So, there’s a lot of exciting progress in RLHF, and with these tools, we can expect to see big improvements in the field.
In Conclusion
I hope you found the article on Reinforcement Learning from Human Feedback (RLHF) informative and engaging. RLHF is an exciting area of research that seeks to bridge the gap between machine learning algorithms and human intuition. The article delved into the mechanics of RLHF, exploring its key features, benefits, and limitations.
If you would like to learn more about RLHF, I encourage you to explore the references listed below. These resources offer a deeper understanding of the theoretical foundations and practical applications of RLHF.
Thank you for taking the time to read this article, and I hope it has been a valuable addition to your knowledge of artificial intelligence and machine learning.
References:
- https://huggingface.co/blog/rlhf
- https://www.unite.ai/what-is-reinforcement-learning-from-human-feedback-rlhf/
- https://openai.com/research/learning-from-human-preferences








