 A Comprehensive Survey
A Comprehensive Survey
Large Language Models (LLMs), like intelligent text generators, are getting good at sounding like humans. But there’s a big problem — sometimes they make things up! This can be a huge issue when we use them in real-world situations, like summarizing medical records or financial reports. The reason behind this is that during their training, they read tons of stuff from the internet. This makes them great at talking but prone to picking up biases, misunderstanding things, or changing information to match what they see.
This article looks at 32 tricks people have developed to fix this “making things up” problem in LLMs. Some cool ones are Retrieval Augmented Generation, Knowledge Retrieval, CoNLI, and CoVe. We’ve also sorted them into groups based on how they use data, what tasks they’re suitable for, how they get feedback, and what kind of info they pull in. This helps us see how people are trying to stop LLMs from making stuff up.
But it’s not all sunshine and rainbows. These tricks have their challenges and limits. This article breaks down what those are, giving a good starting point for future research on ensuring LLMs stay on a creative tangent when we need them to stick to the facts.
Content Source: https://arxiv.org/abs/2401.01313
Utilization of Knowledge Graph
Knowledge graphs (KGs) are like organized maps of information. They hold details about different things, like people, places, or items, along with their characteristics and connections. These graphs help computers make sense of the relationships and meanings behind the data. People use knowledge graphs to think about complex ideas, analyze data, and find information quickly. Researchers have also explored using knowledge graphs in studies related to hallucinations.
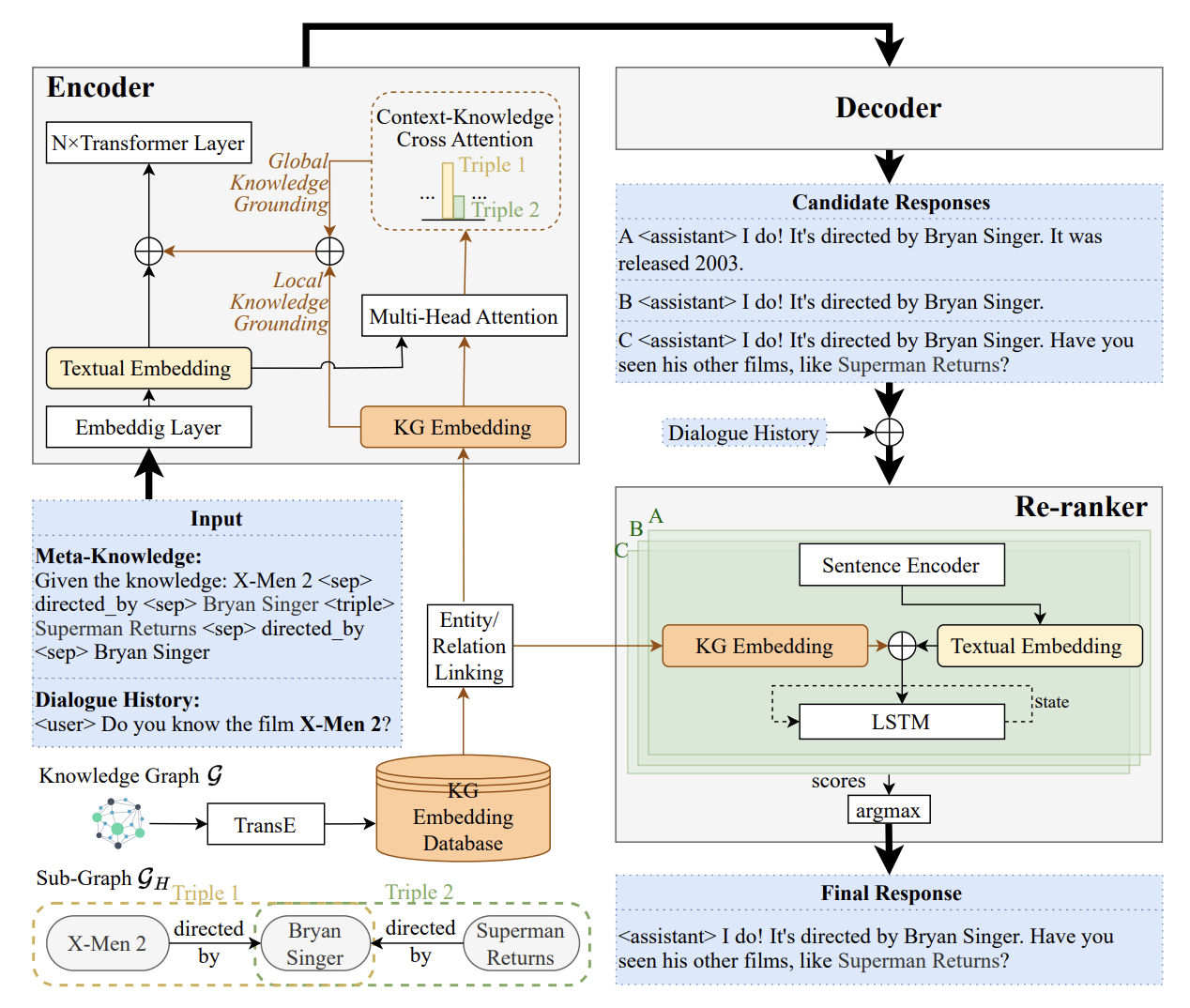
#1 Reducing Hallucination in Open-Domain Dialogues with Knowledge Grounding (RHO)
RHO is a system designed to make chatbots better at giving accurate and relevant conversation responses. It uses information from a knowledge graph (KG) like a database of connected facts. RHO pays special attention to linked entities, and relation predicates in the KG to avoid making things up, which can happen in regular chatbot responses.
To improve the quality of responses, RHO uses a conversational reasoning model. This model helps reorganize the generated answers to be more sensible. Additionally, RHO employs local (specific to the conversation) and global (general knowledge) grounding strategies to ensure the responses are faithful to the input.
Interestingly, RHO can better understand and use information from the ongoing conversation. It focuses on relevant knowledge by looking at connected subgraphs (related facts) and pays attention to them when generating responses. Using various knowledge and reasoning techniques, RHO combines external knowledge with ongoing conversation, making the responses more accurate and reducing the chances of making things up.
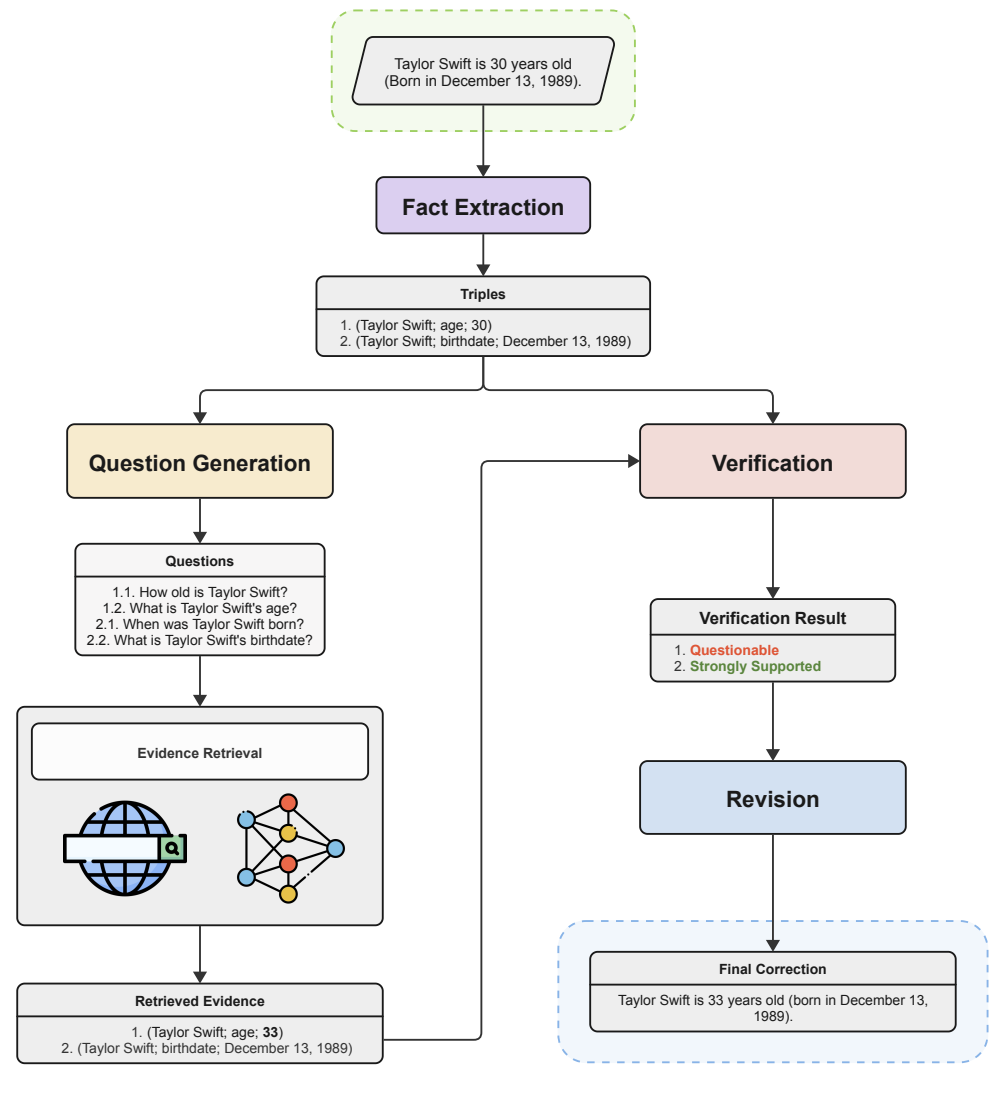
#2 Factual Error Detection and Correction with Evidence Retrieved from External Knowledge (FLEEK)
FLEEK is an intelligent tool that helps people fact-check information easily. It works with any model and is user-friendly. FLEEK can identify possible facts in a given text by itself. It then generates queries for each fact, searches the web, and gathers supporting data from knowledge graphs.
After collecting evidence, FLEEK uses it to confirm the accuracy of the facts and suggests corrections to the original text. The process is easy to understand because the evidence, questions, and facts all represent the information used for verification.
Content Source: https://machinehack.com/story/current-state-of-hallucination-mitigation-techniques-in-large-language-models








