Read original: arXiv:2403.00801 - Published 05/11/2024 by Qiaoyu Tang, Jiawei Chen, Zhuoqun Li, Bowen Yu, Yaojie Lu, Cheng Fu, Haiyang Yu, Hongyu Lin, Fei Huang, Ben He and 3 others
Self-Retrieval: An Innovative Approach to Information Retrieval
The concept of Self-Retrieval represents a significant advancement in the field of information retrieval (IR) by utilizing a single large language model (LLM) to perform all necessary functions within the retrieval process. This approach aims to unify query understanding, document retrieval, and result summarization into one cohesive system.
Overview of Self-Retrieval
Self-Retrieval leverages the capabilities of modern LLMs, such as GPT-3, to handle tasks traditionally divided among multiple components in IR systems. The architecture is designed to internalize the retrieval corpus through self-supervised learning, transforming the retrieval process into sequential passage generation while also performing relevance assessments for reranking documents.
Key Components of Self-Retrieval
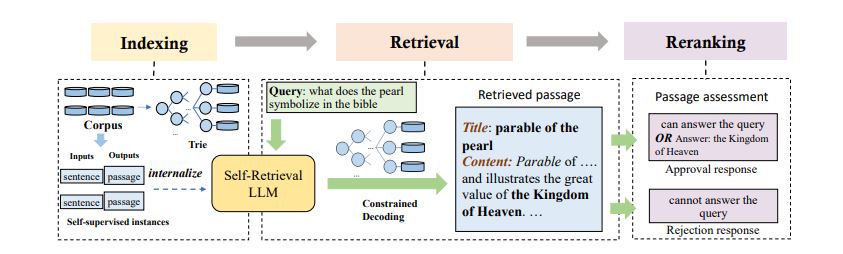
Self-Retrieval operates through three primary steps:
- Indexing: The LLM internalizes the document corpus, creating a natural language index that allows for efficient retrieval.
- Retrieval: Using the generated index, the LLM retrieves relevant passages based on user queries.
- Self-Assessment: The model evaluates and ranks the retrieved passages to ensure high relevance and quality of results.
Advantages of Self-Retrieval
The integration of all IR functions into a single model offers several advantages:
- End-to-End Processing: By consolidating query understanding and document retrieval into one model, Self-Retrieval enhances efficiency and reduces the complexity associated with traditional IR systems.
- Improved Performance: Experimental results indicate that Self-Retrieval outperforms conventional retrieval methods, showing an average improvement of 11% in metrics like Mean Reciprocal Rank (MRR) compared to existing dense and sparse retrieval baselines.
- Flexibility with Query Types: The model can effectively handle a variety of query formats, ranging from simple keyword searches to complex natural language questions.
Challenges and Considerations
Despite its promising capabilities, the Self-Retrieval approach also faces challenges:
- Scalability: The paper does not extensively address how well this model would scale with very large document collections or how it would adapt to dynamic updates in the corpus.
- Transparency: The “black box” nature of LLMs raises concerns about understanding and explaining how decisions are made during retrieval and summarization processes, which is critical for applications requiring transparency.
Conclusion
Self-Retrieval represents a forward-thinking approach to building information retrieval systems that capitalize on the strengths of large language models. By integrating all essential functions into one model, it not only simplifies the architecture but also enhances performance across various tasks. As research continues in this area, further exploration will be necessary to address existing limitations and fully realize its potential in real-world applications.
FAQs on the Self-Retrieval Model
How does the self-retrieval model handle complex natural language queries?
The self-retrieval model effectively manages complex natural language queries by leveraging the advanced language understanding capabilities of large language models (LLMs). It can interpret various query types, from simple keyword searches to intricate questions, by internalizing the retrieval corpus through self-supervised learning. This allows the model to generate relevant document passages and coherently summarize results, all within a single framework.
What are the main challenges of scaling self-retrieval to large document collections?
Scaling self-retrieval to large document collections presents several challenges:
- Indexing Efficiency: As the size of the document collection increases, efficiently indexing and internalizing the corpus becomes more complex. The model must maintain performance without compromising retrieval speed.
- Memory Constraints: Larger collections require more memory for the LLM to store the internalized knowledge, which can limit the size of documents it can handle simultaneously.
- Dynamic Updates: Keeping the model updated with changes in the document collection poses a challenge, as it needs to re-internalize new or modified documents without extensive retraining.
How does self-retrieval compare to traditional information retrieval systems in terms of performance?
Self-retrieval significantly outperforms traditional information retrieval systems. Experimental results indicate that it achieves an average improvement of 11% in Mean Reciprocal Rank (MRR) compared to leading sparse and dense retrieval methods. This enhanced performance is attributed to its end-to-end architecture, which integrates query understanding, document retrieval, and result summarization into a single model, eliminating the inefficiencies associated with separate components.
What task formats were explored to enable self-retrieval in the LLM?
The researchers explored several task formats for enabling self-retrieval:
- Prompting the LLM with Queries: The model is provided with query text to retrieve and summarize relevant documents.
- Concatenating Queries with Candidate Documents: Each candidate document is concatenated with the query, allowing the LLM to predict relevance scores.
- Multi-task Training: The LLM is trained on a mix of tasks that include query understanding, document retrieval, and summarization.
How does self-supervised learning contribute to the self-retrieval process?
Self-supervised learning (SSL) plays a crucial role in the self-retrieval process by enabling the LLM to internalize the corpus during training. Through SSL, the model learns to create supervisory signals from the data itself rather than relying on external labels. This approach allows it to capture essential features and relationships within the data, facilitating efficient indexing and retrieval capabilities. By using SSL, the LLM can effectively memorize and organize knowledge from a large corpus, enhancing its performance in generating relevant document passages.
Citations: https://arxiv.org/abs/2403.00801








