The paper “Mobility VLA: Multimodal Instruction Navigation with Long-Context VLMs and Topological Graphs” presents a novel approach to enable intelligent robots to understand and follow multimodal instructions in complex environments.

The key innovations are:
- Multimodal Instruction Navigation with Demonstration (MINT): This involves physically guiding the robot around the environment while providing verbal explanations, allowing the robot to learn associations between visual cues, language, and actions.
- Hierarchical Vision-Language-Action (VLA) Navigation Policy: This combines the robot’s understanding of the environment with logical reasoning to interpret and execute instructions involving natural language, gestures, and visual cues.
- Long-Context Vision-Language Models (VLMs) and Topological Graphs: The robot uses VLMs with extended context windows to build a rich representation of the environment, which is further enhanced by topological graphs capturing spatial relationships.
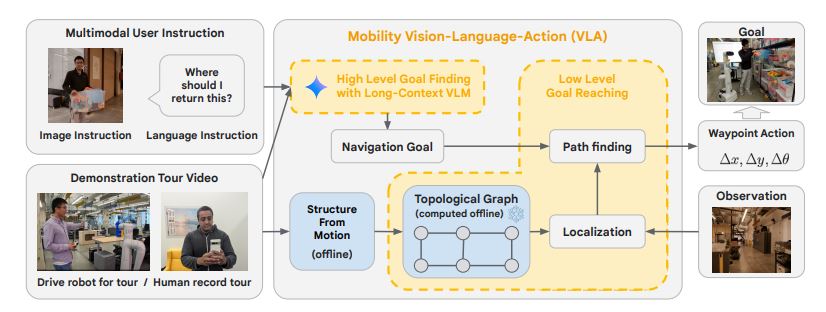
Multimodal Instruction Navigation with Demonstration (MINT)
The researchers first introduced the robot to the office environment through a “multimodal instruction navigation with demonstration” (MINT) approach. In this process, a human guide physically led the robot around the office while providing verbal explanations of the different landmarks and areas. This allowed the robot to learn associations between visual cues, language, and the corresponding actions required to navigate the space.
Hierarchical Vision-Language-Action (VLA) Navigation Policy
To enable the robot to interpret and follow multimodal instructions, the researchers developed a hierarchical Vision-Language-Action (VLA) navigation policy. This policy combines the robot’s understanding of the environment, gained through the MINT process, with logical reasoning capabilities to interpret and execute instructions involving natural language, gestures, and visual cues.
The VLA policy operates in a hierarchical manner, first understanding the high-level intent of the instruction, then breaking it down into a sequence of lower-level actions to be executed in the environment.
Long-Context Vision-Language Models (VLMs) and Topological Graphs
A vital component of the VLA policy is the use of long-context Vision-Language Models (VLMs) and topological graphs to represent the robot’s understanding of the environment. The long-context VLMs allow the robot to build a rich representation of the office space, capturing details and relationships that would be missed by models with shorter context windows.
Additionally, the researchers used topological graphs to further enhance the robot’s spatial understanding, capturing the relative positions and connections between different areas of the office. This combination of long-context VLMs and topological graphs enabled the robot to navigate the environment effectively and interpret instructions that involved complex spatial relationships.
Demonstration and Results
The researchers demonstrated the capabilities of their Mobility VLA system by having the robot navigate the Google DeepMind offices and follow various multimodal instructions from human guides. The robot was able to successfully interpret and execute tasks such as guiding a person to a suitable location for drawing and following written instructions to reach a specific area of the office.
The team reported a success rate of approximately 90% in over 50 interactions with employees, indicating significant progress in human-robot interaction and the potential of this approach for real-world applications.
Citation








